Platform for Analyzing Opinions of Twitter Users
Twitter as a Data Mining Platform
The rise in popularity of social networks makes them an increasingly important source of information about people’s opinions on various topics, such as celebrity life, the activities of different companies and the success of their brands, political issues, and much more. Market researchers, social scientists, politicians, and celebrities alike use social networks to obtain information on matters of interest to them and develop a further course of action based on the data gathered. However, this information is expressed in natural languages, thus becoming an ever-increasing volume of unstructured data that is difficult to process.
Twitter is the eighth most popular online resource in the world. Its users generate over 500 million messages daily. This poses a problem in automating the analysis of such large volumes of unstructured data. In addition to enjoying widespread popularity, Twitter is notable for imposing a message length restriction of 140 characters. This leads to a higher degree of coherence in the message text. Thus, Twitter provides ample opportunities to use Natural Language Processing (NLP) tools and algorithms for data mining.
Our client is IBM, and for many years it has been building software solutions for processing structured and unstructured data. IBM created its own content analysis methodology and asked us to develop software to verify the applicability of its approach for analyzing Twitter messages.
Solution
We designed and developed an application that collects Twitter message threads on specific topics, normalizes text, analyzes sentiments, and marks them with special tags. The software then processes these tags using statistical analysis and visualizes the results over a given period in real time.
Twitter's popularity among users necessitates the analysis of large volumes of data streams. The traditional approach requires large data storage volume and significant computing power, as well as typically being incapable of handling incoming data and displaying results in real time. We used a different approach to work effectively with Big Data. According to this approach, a data stream is filtered by topic and the yielded data set is immediately analyzed. The results for the processed data are available to users with minimal delay.
To display the results of the analysis not only in real time, but also historically, parsed streams are marked with timestamps. Based on these stamps, a stream is divided into separate “windows”. This allows a user to calculate and display statistics for the entire period of data collection as well as for specific time intervals.
The mechanism we developed for message processing works directly with Twitter API, as well as with the GNIP aggregator that provides access to data streams not only from Twitter, but also from other social applications and networks, e.g. Facebook, Google+, etc.
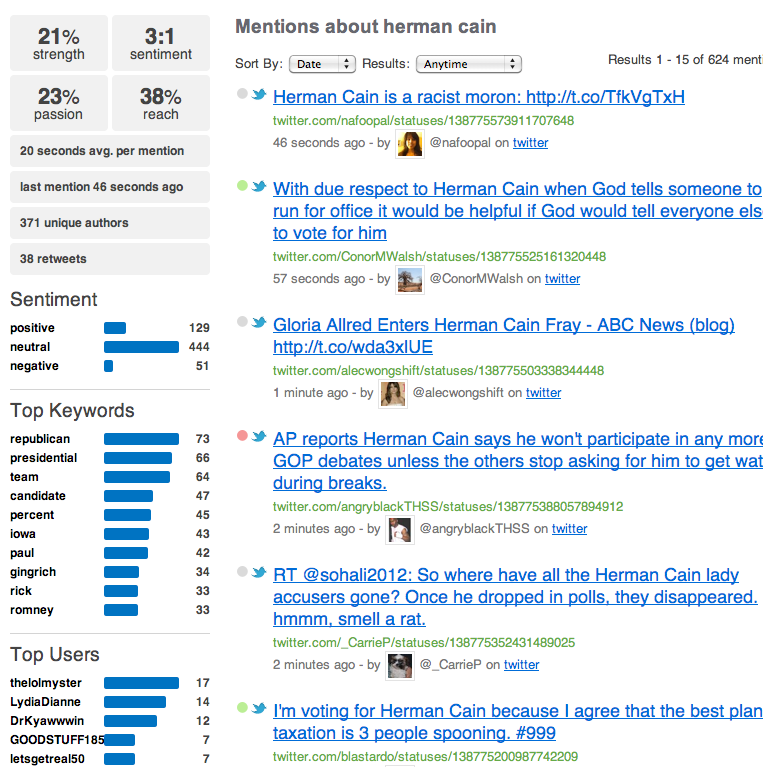
One of the possible applications of NLP algorithms to Twitter messages is determining user opinion on a chosen topic. IBM asked us to develop an application for sentiment analysis of Twitter messages. The software should find Twitter users' opinions expressed in messages and determine their emotional coloring (positive, negative, or neutral) in relation to a chosen topic. The application should classify the polarity of the message threads on Twitter in real time. The goal was to use the application to automate the recognition, interpretation, and processing of people’s opinions about sports championships, political debates, television shows, etc.
IBM provided us with a previously developed basic sentiment dictionary with words and phrases and their corresponding evaluation (neutral, positive, or negative). We used IBM LanguageWare tools to create more accurate language models based on the sentiment dictionary for correctly classifying the polarity of messages. At the same time, it takes into account the particular topic and the characteristics of the target audience vocabulary, including idioms, jargon, and other well-established expressions, as well as other language constructs which require more complex lexical analysis.
Since even content pre-filtering cannot guarantee the system input will not be overloaded with more information than it can handle at any given time, we designed and developed the system components specifically for deployment in distributed systems. This enables scalable and elastic solutions. For example, the developed linguistic models were delivered as UIMA modules, which can be run with appropriate wrappers in different environments. We successfully used IBM InfoSphere Streams and Apache Storm as platforms for distributed stream processing.
The ultimate goal of the project was to create a software solution for clearly and easily displaying the collected data in a visually appealing graphical format. The application displays the results of analyzed Twitter message threads as custom diagrams showing the proportion of positive, negative, and neutral opinions of Twitter users on a selected topic. The application visualizes data in real time, ensuring that the information on the chart is always current. The user can see the results for the entire data set or specify the time interval for the messages that need to be analyzed.
The application was used for the first time to analyze fan reaction during the 2012 US Open. Twitter users' opinions about the tournament participants were displayed on the championship’s interactive scoreboard.
Later, the concept of data processing used in this project was successfully applied in other scenarios to classify the polarity of Twitter messages. For example, the same approach was used to analyze Twitter audience attitudes towards the US presidential candidates during the 2012 election.